Continuation of Udacity project
This time we will go through this project with Python using scikit-learn and see how the results differ from eachother from previous iteration.
We’re tasked with predicting how much money a fictional company in the mail-order catalog business can expect to earn from sending out a catalog to new customers.
Overview
This project has previously been finished using Alteryx analytics software as project work for Udacity’s Predictive Analytics for Business nanodegree.
This task will involve building a linear regression model with scikit-learn and applying the results in order to provide a recommendation to this fictional management.
We have two excel files to work with:
1. customers.xlsx - existing customers
2. mailinglist.xlsx - new customers
The Business Problem
Last year the company sent out its first print catalog, and is preparing to send out this year’s catalog in the coming months. The company has 250 new customers from their mailing list that they want to send the catalog to. Determine how much profit the company can expect from sending a catalog to these customers. Management does not want to send the catalog out to these new customers unless the expected profit contribution exceeds $10,000.
Business and Data Understanding
- We need to predict if this catalog campaign is a good idea. Should the company send out these catalogs to new customers? How much revenue can this company expect to make if they send their new catalog to these 250 customers? Is it profitable considering all the costs and possibility that customer might not make a purchase at all?
- What data is needed to inform those decisions?
- Possible revenue from each client
- Cost of each catalog
- Average past sales
- Average gross margin for each product
- Average number of products purchased
- Probability that customer will buy
- Customer segment
EDA
In the exploratory data analysis part we were able to see that our existing customer data on response to the last catalog is imbalanced towards ‘No’.
customers['Responded_to_Last_Catalog'].value_counts()
No 2204
Yes 171
Name: Responded_to_Last_Catalog, dtype: int64
Because we are working with fake data, we already have the new customers probable response to our new catalog in our data, with a probability between 0 and 1. If we did not have this we would have to calculate the probability with a logistic regression model and training the model with such an imbalance(13:1) would be problematic.
Choosing features
For our linear regrssion features we have kept Customer_Segment, Avg_Sale_Amount and Avg_Num_Products_Purchased. Because we want to use Customer_Segment in our model as well, but is a categorical variable, we need to convert it to dummy variables.
feats['Customer_Segment'].value_counts()
Store Mailing List 1108
Loyalty Club Only 579
Credit Card Only 494
Loyalty Club and Credit Card 194
Name: Customer_Segment, dtype: int64
Convert the 4 categorical values to dummy variables:
seg_dummies = pd.get_dummies(feats['Customer_Segment'], prefix='Seg_', drop_first=True)
feats = pd.concat([feats, seg_dummies], axis=1)
feats = feats.drop('Customer_Segment', axis=1)
Linear regression
We will use Avg_Sale_Amount from old customers’ data as the target variable to predict the average sale amount for new customers.
After splitting our data for testing and training the Best linear regression equation was the following:
Y = 284.48 + 70.68 * Avg_Num_Products_Purchased - 144.33 * (If Type: Loyalty Club Only) + 267.64 * (If Type: Loyalty Club and Credit Card) - 231.33 * (If Type: Store Mailing List) + 0 * (If Type: Credit Card Only)
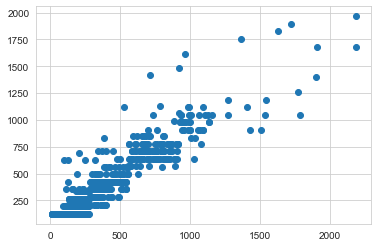
R-squared 0.8485331100796489
MAE: 89.31308194968375
MSE: 17006.43868059899
RMSE: 130.40873697954055
feats['Avg_Sale_Amount'].describe()
count 2375.000000
mean 399.774093
std 340.115808
min 1.220000
25% 168.925000
50% 281.320000
75% 572.400000
max 2963.490000
Name: Avg_Sale_Amount, dtype: float64
Average sales for new customer
Now we are ready to deploy our linear regression model on new customers data and then multiply the predicted revenue with given customer’s probability of making the purchase:
Probable_Revenue = (Predicted_Avg_Sale_Amount) * (Answer_Yes)
Results
Does the expected profit contribution exceed $10,000?
Probable revenue is multiplied with average gross margin of all products, which is 50% and deducted the cost of each catalog which is $6.50:
Probable_Revenue * 0.5 – 6.50
prob_revenue['Rev_Minus_cost'] = (prob_revenue['Prob_Revenue']*0.5)-6.50
prob_revenue['Rev_Minus_cost'].sum()
22012.86333703793
The Final Profit from the new catalog is expected to be $22,012.86 which would be the probable profit made from sending new catalogs out to given 250 customers.
—Notes—
The results compared with previous rendering of linear regression model in Alteryx software for the same data is almost the same.
Their R-squared values were slightly different, where Alteryx model calculated 0.8369 and our model in sckit-learn 0.8485.
So Alteryx predicted the final profit to be $21,987.44, which results in a $25.42 difference.